From the other NLP work/investigations, I have the basic required queries to import, clean-up and query a transcript into Neo4j. Next step is to bring this together into a small web app to manage this for me (and hopefully present some visuals – i can finally look at d3js, which my team use on our internal site to great effect)
Updating the model a little.
From the work so far i;m planning to make the following changes to my overall NLP model
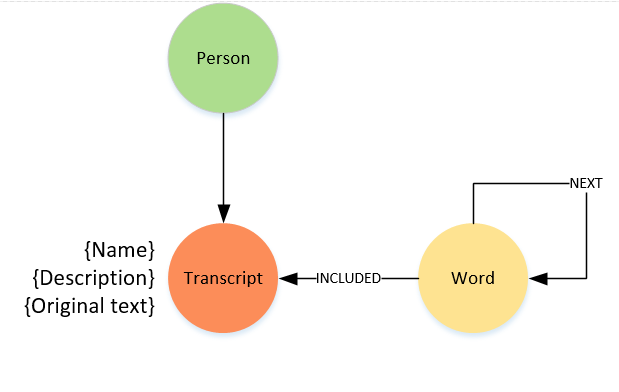
as well as the word adjacency graph, I will also store the original text in its complete form as part of the transcript.
The app
libraries used
- node.js
- express
- neo4j-driver
- ejs
- morgan
- body-parser
Keeping this pretty basic for now, (not quite green screen:) ) with some very simple pages to add and review a transcript.
The basic parts are now running
- adding a transcript
- review a transcript
- review by person
add a twitter user? – more on that later
Cleaning up the text
This has been the hardest part, although mainly due to my lack of recent javascript writing.
Simple punctuation clean-up
var s = TranscriptWords;
varpunctuationless=s.replace(/'[.,\/#!$%?\^&\*;:{}=\-_`~()]/g,"");
varfinalTranscriptWords=punctuationless.replace(/'/g, "\#");
varfinalTranscriptWords2=finalTranscriptWords.replace(/\s{2,}/g," ");
stop words
Currently just have a list of words; was thinking about moving these to a set of nodes within the Graph and querying against them – but very little gain over what I really want to do. The only lesson here were the escape codes required to ensure the ‘ in words such as don’t didn’t close the string and a single escape of \’ wasn’t enough when pulled into the neo query – some a double escape words \\’
part of the stopWords variable
var stopWords="'all','am','an','and','any','are','aren\\'t'";
current status
all the DXC market leading play papers have been saved as text and imported in; without any additional clean-up steps from the “save as text” after opening the pdf in MS Word
